Quando uma empresa diz que quer "treinar a IA no nosso conteúdo", quase sempre o que ela precisa não é treinar nada — é conectar a IA ao conhecimento que já existe. E essa conexão tem um nome técnico que vale a pena conhecer: RAG.
O que é RAG e por que o nome importa?
RAG é a sigla em inglês para Retrieval-Augmented Generation, em português algo como "geração aumentada por recuperação". O nome descreve o mecanismo: antes de gerar uma resposta, o sistema recupera trechos relevantes de uma base de documentos e aumenta o contexto enviado ao modelo com esse material.
O conceito surgiu de uma necessidade prática: modelos de linguagem grandes (LLMs) são treinados com dados até uma determinada data e não têm acesso automático ao conhecimento interno de nenhuma empresa específica. Eles sabem muito sobre o mundo em geral, mas não sabem nada sobre o manual de procedimentos do seu RH, as cláusulas do contrato padrão do seu jurídico ou as perguntas frequentes do seu produto.
RAG resolve isso sem modificar o modelo. Em vez de ensinar o modelo a memorizar os seus documentos, você ensina o sistema a buscar a informação certa no momento certo e entregá-la ao modelo como contexto para a resposta.
Para entender melhor o que são esses modelos por baixo, vale a leitura de o que é um LLM.
Fine-tuning, RAG e contexto longo: qual a diferença real?
Essa é a confusão mais comum. As três abordagens resolvem problemas parecidos por caminhos distintos.
Fine-tuning (ajuste fino) é o processo de continuar o treinamento de um modelo já existente com dados novos e específicos. O modelo absorve esses dados na forma de pesos ajustados — é como se as informações fossem "gravadas" no cérebro do modelo. Fine-tuning é caro, demorado, exige expertise em machine learning e precisa ser refeito toda vez que os dados mudam. Faz sentido quando você quer mudar o estilo ou o comportamento do modelo (tom de voz, formato de resposta, domínio muito especializado), não quando quer que ele conheça documentos corporativos que mudam com frequência.
Contexto longo é uma abordagem mais direta: você simplesmente cola todos os documentos relevantes dentro da janela de contexto do modelo a cada chamada. Funciona para bases pequenas, mas escala mal — janelas de contexto têm limites e custos, e empurrar centenas de páginas em cada consulta é ineficiente.
RAG fica no meio-termo ideal para a maioria das empresas: os documentos ficam armazenados em um banco vetorial externo. A cada pergunta, o sistema recupera apenas os trechos mais relevantes e os injeta no contexto. O modelo vê pouca informação, mas a informação certa.
| Abordagem | Custo | Atualização | Privacidade | Melhor para |
|---|---|---|---|---|
| Fine-tuning | Alto | Retreinar do zero | Depende do provedor | Mudar comportamento/estilo do modelo |
| Contexto longo | Médio | Imediato | Sob controle | Bases pequenas, uso pontual |
| RAG | Baixo a médio | Imediato | Sob controle total | Bases de conhecimento corporativo |
Para empresas que querem que a IA conheça seus documentos, RAG quase sempre é a escolha certa.
Como o RAG funciona na prática, passo a passo?
O fluxo tem duas fases bem distintas: a ingestão dos documentos e o momento da consulta.
Fase 1 — Ingestão
Primeiro, os documentos são carregados no sistema: PDFs, arquivos Word, páginas de wiki, planilhas, textos de sites. O sistema lê esses arquivos e os divide em pedaços menores, chamados de chunks — fragmentos de algumas centenas de palavras cada, com alguma sobreposição entre eles para não perder contexto nas bordas.
Cada chunk é então convertido em um embedding: uma representação matemática em vetor de alta dimensão que captura o significado semântico do texto. Dois trechos que falam sobre o mesmo assunto — mesmo com palavras diferentes — ficam próximos nesse espaço vetorial. Esses vetores são armazenados em um banco vetorial (ferramentas como Chroma, Pinecone, Weaviate ou pgvector).
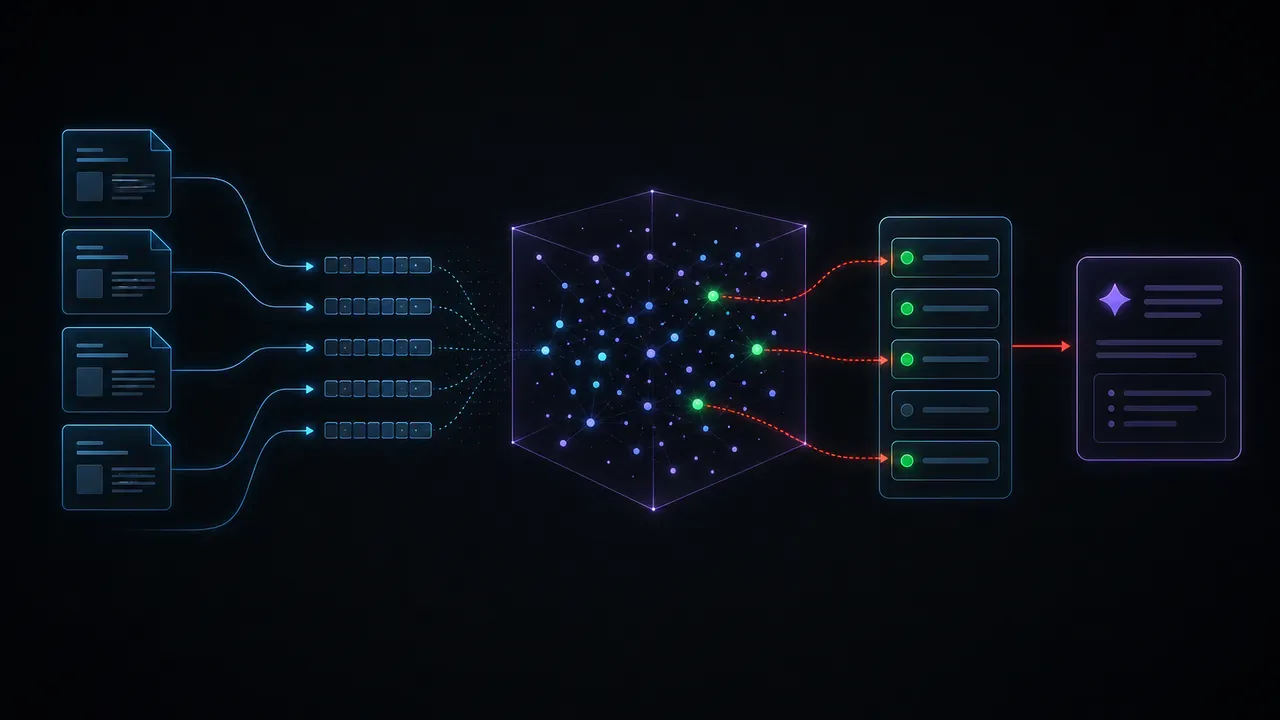
Fase 2 — Consulta
Quando um usuário faz uma pergunta, o sistema converte essa pergunta em um embedding usando o mesmo modelo de embeddings. Depois faz uma busca por similaridade no banco vetorial: quais chunks têm vetor mais próximo ao da pergunta?
Os chunks mais relevantes são recuperados e montados em um bloco de contexto que é enviado junto com a pergunta ao modelo de linguagem. O modelo então gera a resposta ancorado naquele material — com a opção de citar a fonte exata de onde a informação veio.
O resultado: uma resposta que usa a linguagem natural do LLM, mas que está fundamentada nos seus documentos reais.
Por que RAG reduz alucinações?
Alucinação é o termo técnico para quando um modelo de linguagem inventa informações que parecem plausíveis mas são falsas. É um problema inerente à arquitetura dos LLMs: eles geram texto estatisticamente provável, e quando não sabem a resposta, podem "completar" com algo que soa certo.
RAG ataca esse problema diretamente. Em vez de o modelo responder a partir do que "lembra" do treinamento, ele responde a partir de trechos concretos que foram recuperados. Se a informação não está nos documentos indexados, o sistema pode simplesmente informar que não encontrou resposta — em vez de inventar.
Isso não elimina alucinações por completo, mas reduz drasticamente a taxa em contextos corporativos onde a base de conhecimento é bem curada. A qualidade da resposta está atrelada à qualidade dos documentos ingeridos.
Esse ponto conecta diretamente com a questão de privacidade: os seus documentos não saem do seu ambiente. Diferente de um fine-tuning feito em infraestrutura de terceiros, em uma arquitetura RAG bem desenhada os dados ficam no banco vetorial que você controla. Para empresas com requisitos de conformidade, isso muda o jogo.
Quais são os casos de uso mais comuns?
Atendimento ao cliente com base de conhecimento. Em vez de treinar atendentes humanos para decorar centenas de FAQs, uma IA com RAG consulta a base atualizada em tempo real e responde com precisão. Qualquer mudança na política ou produto basta atualizar o documento — sem retreinar nada.
Suporte interno e onboarding. Novos colaboradores têm dúvidas sobre processos, benefícios, ferramentas. Uma IA conectada ao manual do funcionário, às políticas de RH e aos procedimentos internos responde essas perguntas 24 horas por dia, com rastreabilidade da fonte.
Consulta a contratos e políticas jurídicas. Equipes jurídicas e de compliance lidam com volumes grandes de documentos. Uma IA com RAG pode localizar cláusulas específicas, identificar obrigações e prazos, e cruzar informações entre contratos — tarefas que tomariam horas de leitura manual. Para ver como isso se encaixa em fluxos maiores, o post sobre automações e integrações com IA aprofunda o tema.
Suporte técnico com manuais de produto. Empresas industriais ou de tecnologia têm documentação técnica extensa. Uma IA com RAG pode guiar técnicos por procedimentos de manutenção, troubleshooting e instalação sem que o técnico precise folhear centenas de páginas.
Relatórios e síntese de documentos internos. Conectada a bases de dados de relatórios anteriores, a IA pode responder perguntas analíticas sobre o negócio com base nos documentos reais — sem acessar dados brutos. O post IA otimizando relatórios massivos explora esse uso em mais detalhe.

O que preciso ter para implementar RAG na minha empresa?
Tecnicamente, os componentes de uma arquitetura RAG são:
- Os documentos a serem indexados (PDFs, textos, bases de dados estruturadas)
- Um pipeline de ingestão que lê, fragmenta e embeda esses documentos
- Um banco vetorial para armazenar e consultar os embeddings
- Um modelo de linguagem que gera as respostas
- Uma camada de orquestração que conecta consulta, recuperação e geração
Nenhum desses componentes exige infraestrutura extraordinária. Existem soluções open source maduras para cada etapa, e a implementação pode rodar tanto em nuvem quanto em servidores próprios — o que é relevante para empresas com requisitos de privacidade mais rígidos.
A parte mais crítica não é técnica: é a curadoria dos documentos. Uma base de conhecimento desatualizada, mal escrita ou desorganizada vai produzir respostas ruins independentemente da qualidade do modelo. Garbage in, garbage out se aplica aqui.
Para contexto sobre as decisões de infraestrutura envolvidas — nuvem versus self-hosted — o post IA self-hosted vs nuvem cobre esse tradeoff diretamente. E se a questão for DevOps e operação dessa infraestrutura, a área de DevOps da MaxVision trata exatamente disso.
Perguntas Frequentes
RAG realmente "treina" a IA nos meus documentos?
Não, no sentido técnico do termo. O modelo de linguagem em si não é modificado. O que acontece é que seus documentos ficam disponíveis como contexto para o modelo consultar a cada resposta. A confusão é comum porque o resultado prático — uma IA que "sabe" sobre seus documentos — parece um treinamento, mas o mecanismo é diferente.
Meus dados ficam seguros? A OpenAI ou outro provedor vai ver os meus documentos?
Depende da arquitetura. Em uma implementação self-hosted, seus documentos ficam exclusivamente nos seus servidores e nunca saem do seu ambiente. Mesmo usando um LLM em nuvem, é possível enviar apenas os trechos relevantes por chamada de API sem armazenar dados no provedor. A decisão de onde hospedar cada componente define o nível de exposição.
Quanto tempo leva para implementar RAG?
Para uma base de conhecimento razoavelmente organizada (algumas centenas de documentos), um sistema RAG funcional pode ser colocado em operação em semanas, não meses. A maior parte do tempo vai para curadoria e preparação dos documentos, não para a infraestrutura técnica em si.
RAG funciona com documentos em português?
Sim. Os modelos de embeddings e os LLMs modernos têm suporte sólido ao português. Alguns modelos funcionam melhor em inglês, mas há opções competentes treinadas com dados em português, além de modelos multilíngues que performam bem na prática.
Qual a diferença entre RAG e um simples mecanismo de busca?
Uma busca tradicional retorna documentos inteiros com base em palavras-chave. RAG recupera os trechos mais semanticamente relevantes para a pergunta e os usa como base para gerar uma resposta em linguagem natural, com síntese e capacidade de cruzar informações de múltiplas fontes. A busca encontra onde está a informação; o RAG lê e responde.
Conclusão
"Treinar a IA nos documentos da empresa" é um objetivo legítimo e alcançável. Na grande maioria dos casos, o caminho não passa por um processo custoso de fine-tuning — passa por RAG: conectar um modelo de linguagem à sua base de conhecimento de forma inteligente, mantendo os dados sob seu controle e a resposta ancorada em fontes verificáveis.
O resultado é uma IA que fala sobre o seu negócio com precisão, que pode ser atualizada sem retreinar nada e que respeita os requisitos de privacidade que empresas sérias precisam observar.
Se você quer avaliar como essa arquitetura se encaixaria na operação da sua empresa — seja para atendimento, suporte interno, consulta jurídica ou qualquer outro caso — a MaxVision implementa exatamente isso. Fale com a nossa equipe e veja o que faz sentido para o seu contexto.