A pergunta chegou para ficar: IA self-hosted ou API de nuvem? Se você já está rodando automações, experimentando o que é um LLM ou avaliando onde encaixar inteligência artificial nos seus processos, em algum momento vai esbarrar nessa decisão. A resposta depende menos de modismo e mais de quatro variáveis concretas: seus dados, seu orçamento, seu time e o nível de controle que você precisa. Vamos direto ao ponto.
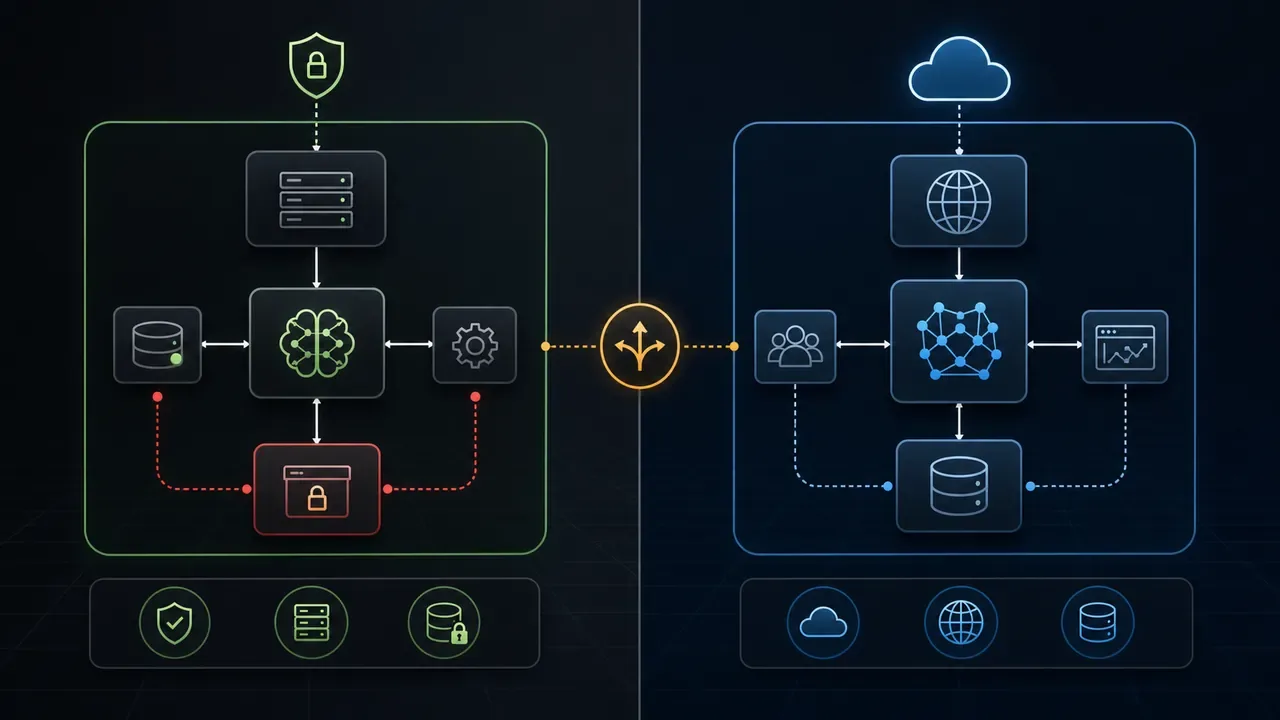
O que é, de fato, IA self-hosted?
Self-hosted significa que o modelo roda dentro de um servidor que você controla: pode ser um VPS, um servidor dedicado na sua empresa ou uma VM em cloud privada. O ponto central é que o dado não sai da sua infraestrutura para ser processado.
Ferramentas como Ollama permitem subir um LLM local com um único comando e expor uma API compatível com o formato OpenAI. O vLLM é a escolha quando o volume de requisições exige throughput alto e otimização de memória GPU. Para busca semântica e RAG (Retrieval-Augmented Generation), bancos como pgvector (extensão do PostgreSQL) e Qdrant armazenam embeddings localmente e respondem a queries de similaridade sem depender de serviço externo.
A stack típica em produção se parece com isto:
Cliente / Aplicação
|
API Gateway
|
Ollama / vLLM <--- modelo rodando localmente
|
pgvector / Qdrant <--- base de conhecimento
|
n8n / orquestrador <--- workflows de automação
Se você ainda não conhece o n8n como orquestrador de fluxos, o artigo o que é n8n explica como ele conecta esses componentes sem exigir código extenso.
Por que tantas empresas ainda escolhem a nuvem?
A API de nuvem tem uma vantagem inegável: você começa a gerar valor no mesmo dia. Sem servidor para provisionar, sem modelo para baixar, sem infraestrutura para monitorar. Uma chave de API e alguns reais em crédito já colocam GPT-4o, Claude ou Gemini respondendo perguntas dos seus clientes.
Além da velocidade de entrada, os provedores de nuvem investem pesado em atualizações de modelo. Você não precisa gerenciar versões: quando o provedor lança uma melhoria, você automaticamente se beneficia.
Para protótipos, MVPs e empresas sem time técnico dedicado, essa frição zero é decisiva.
Qual é o real custo de cada caminho?
O custo de API de nuvem parece baixo no início, mas escala de forma imprevisível. Um chatbot que responde 50 mil mensagens por mês com contexto de 800 tokens por turno pode gerar facilmente R$ 2.000 a R$ 6.000 mensais dependendo do modelo escolhido. O custo é variável e indexado ao volume.
No self-hosted, o custo é predominantemente fixo: o servidor. Um servidor com GPU A10G ou RTX 4090 na faixa de R$ 800 a R$ 2.500 mensais consegue servir modelos como Llama 3 70B ou Mistral com throughput razoável para operações médias. Acima de determinado volume, o self-hosted passa a ser mais barato.
A tabela abaixo consolida os principais trade-offs:
| Dimensão | IA Self-Hosted | API de Nuvem |
|---|---|---|
| Custo inicial | Alto (servidor, setup) | Baixo (pay-as-you-go) |
| Custo em escala | Previsivel e fixo | Variavel, escala com volume |
| Privacidade dos dados | Total controle | Dados trafegam para terceiros |
| Conformidade LGPD | Mais simples de demonstrar | Requer DPA e auditoria do provedor |
| Latência | Depende do hardware local | Depende da distancia ao datacenter |
| Qualidade do modelo | Limitada aos modelos open weights | Acesso aos melhores modelos fechados |
| Manutencao | Alta (updates, infra, seguranca) | Baixa (gerenciado pelo provedor) |
| Controle de versao do modelo | Total | Limitado (provedor decide) |
| Disponibilidade | Voce e responsavel pelo uptime | SLA garantido pelo provedor |
| Customizacao (fine-tuning) | Possivel e economico | Possivel mas caro |
Quando os dados sensíveis exigem self-hosting?
A LGPD não proíbe processar dados pessoais em APIs de terceiros, mas exige que haja base legal, finalidade definida e, quando aplicável, contrato de operador (DPA) adequado. O problema prático é que provedores de IA de nuvem têm políticas de uso de dados que nem sempre são compatíveis com o nível de sensibilidade exigido.
Dados que tipicamente exigem self-hosting ou, no mínimo, contratos enterprise com garantias contratuais rígidas:
- Prontuários médicos e dados de saúde (sensíveis por definição na LGPD)
- Dados financeiros de clientes com detalhamento de transações
- Documentos jurídicos com informações de partes em litígio
- Conversas de RH envolvendo processos disciplinares
- Segredos industriais e propriedade intelectual
Se o seu produto processa qualquer uma dessas categorias de forma rotineira, a pergunta não é "self-hosted ou nuvem" — é "como estruturo o self-hosted para operar com segurança".
Segundo pesquisa da IDC de 2024, 67% das empresas europeias e latino-americanas com requisitos regulatórios citam soberania de dados como o principal motivador para adotar infraestrutura de IA privada.
Quando a nuvem é a escolha racional?
Auto-hospedagem não é para todo mundo, e fingir o contrário seria desonesto.
Se o seu time não tem engenheiro capaz de administrar servidor Linux, configurar CUDA, monitorar GPU memory leak e aplicar patches de segurança, a vantagem de privacidade do self-hosted vira risco: um servidor mal configurado é pior do que uma API de nuvem bem configurada.
Cenários em que a nuvem provavelmente ganha:
- Volume baixo a médio com dados não sensíveis
- Time técnico pequeno ou sem especialização em infra
- Prototipagem e validação de produto
- Necessidade dos modelos de ponta (GPT-4o, Claude 3.5 Opus) sem equivalente open weight de qualidade comparável
- Prazo curto para entrar em produção
Existe um meio-termo?
Sim. O modelo híbrido é cada vez mais comum: dados sensíveis e queries que exigem privacidade vão para o modelo local; queries de baixo risco ou que exigem capacidade de raciocínio de ponta vão para a API de nuvem. O roteamento pode ser feito por regra simples no orquestrador.
Outra abordagem intermediária é usar Azure OpenAI ou AWS Bedrock: você acessa os modelos da OpenAI ou Anthropic, mas dentro de uma instância dedicada na conta Azure ou AWS da sua empresa. Os dados não são usados para retreinamento e existem garantias contratuais de isolamento. É um ponto médio entre a facilidade de API e as garantias de privacidade do self-hosted.
Como é na prática: um caso real de self-hosting
Uma empresa de contabilidade com a qual trabalhamos processava extratos bancários e documentos fiscais de clientes via API de nuvem. A operação funcionava, mas o volume mensal gerava custo crescente e, mais importante, os clientes enterprise começaram a questionar para onde iam os dados dos balanços.
A solução foi provisionar um servidor com GPU na estrutura deles, subir Llama 3 70B via vLLM e integrar pgvector para RAG sobre a base de normas da Receita Federal. O custo caiu 40% em relação à API de nuvem no mesmo volume. O argumento de privacidade para os clientes enterprise se tornou concreto e auditável.
O ponto de atenção: levou três semanas para o time de DevOps estabilizar a operação, incluindo monitoramento, reinicialização automática e backup dos pesos do modelo. Self-hosted tem custo de setup real.
Qual é a stack self-hosted mais usada?
Para quem está avaliando o caminho, os componentes mais maduros hoje são:
Serving do modelo:
- Ollama — ideal para desenvolvimento e operações de volume médio. Interface simples, funciona em CPU também (mais lento).
- vLLM — produção com GPU, throughput alto, suporte a batching.
Base vetorial para RAG:
- pgvector — se você já usa PostgreSQL, é a opção com menos overhead operacional.
- Qdrant — banco vetorial dedicado, mais recursos para casos avancados.
Orquestração de workflows:
- n8n self-hosted — conecta o modelo aos sistemas existentes (CRM, ERP, WhatsApp) sem código extenso. Veja mais em o que é n8n.
Observabilidade:
- Langfuse ou Phoenix para rastrear chamadas ao modelo, latência e custo por query.
Quais sinais indicam que é hora de migrar para self-hosted?
Alguns indicadores práticos que costumamos usar na avaliação:
- Custo mensal com API de nuvem ultrapassou R$ 3.000 e o volume segue crescendo
- Clientes ou auditores perguntaram onde os dados são processados
- A latência da API de nuvem gera experiência ruim em casos de uso real-time
- Você precisa de fine-tuning frequente e o custo no provedor inviabiliza iteração
- O modelo de nuvem foi atualizado pelo provedor e quebrou um comportamento que você dependia
Qualquer um desses sinais isolado pode não ser suficiente. Dois ou mais juntos geralmente justificam a avaliação formal.
Perguntas Frequentes
IA self-hosted é mais segura do que APIs de nuvem?
Depende da execução. Um servidor self-hosted bem configurado, com acesso restrito, criptografia em repouso e rede segmentada oferece controle superior. Um servidor mal administrado pode ser menos seguro do que uma API de provedor com SOC 2 Type II. A segurança não é propriedade intrínseca do self-hosting: é resultado de como você opera.
Quais modelos posso rodar em self-hosted?
Os principais são da família Llama (Meta), Mistral, Qwen (Alibaba) e Gemma (Google). A qualidade evoluiu muito: Llama 3 70B tem desempenho próximo ao GPT-4 Turbo em boa parte das tarefas. Para casos que exigem raciocínio complexo de ponta, os modelos fechados ainda levam vantagem.
Preciso de GPU para rodar self-hosted?
Não obrigatoriamente. Modelos menores (7B parâmetros) rodam em CPU, mas com latência alta para produção. Para uso em produção com latência aceitável, GPU é recomendada. Uma RTX 4090 já suporta modelos de 30B quantizados com boa performance.
Self-hosted é compatível com LGPD?
Self-hosted facilita a demonstração de conformidade porque você sabe exatamente onde os dados ficam e quem tem acesso. Mas conformidade vai além do armazenamento: envolve políticas internas, controles de acesso, logs de auditoria e processos para responder solicitações de titulares. O self-hosting é uma peça, não a resposta completa.
Quanto tempo leva para colocar self-hosted em produção?
Para um ambiente de desenvolvimento funcional com Ollama: algumas horas. Para produção estável com monitoramento, failover e pipeline de atualização de modelo: de duas a seis semanas dependendo da maturidade do time de infra e da complexidade da integração com sistemas existentes.
Conclusão
IA self-hosted e API de nuvem não competem: servem perfis diferentes. A nuvem vence em velocidade de entrada, manutenção reduzida e acesso aos modelos de ponta. O self-hosted vence em previsibilidade de custo em escala, soberania de dados e controle operacional.
A decisão mais inteligente começa com uma pergunta simples: quais dados vão passar pelo modelo? Se a resposta inclui categorias sensíveis, reguladas ou estratégicas, a conversa sobre self-hosting se torna obrigatória. Se os dados são genéricos e o time é pequeno, a nuvem provavelmente entrega mais valor com menos fricção.
O que não recomendamos é adiar a decisão por não ter clareza sobre o assunto. Cada mês de uso desatento de API de nuvem com dados sensíveis é um risco regulatório acumulado.
Se você quer avaliar se IA self-hosted faz sentido para a sua operação, o departamento de DevOps e IA Self-Hosted da MaxVision provisiona e opera toda a stack — Ollama, vLLM, pgvector, Qdrant e integrações — no servidor do cliente. Conheça também o departamento de Inteligencia Artificial para casos em que a nuvem é o caminho certo. Para conversar sobre o seu cenário especifico, entre em contato.