Cabe um livro inteiro num único prompt de IA — e isso não é hype de marketing, é o que o Google Gemini 1.5 Pro tornou possível em fevereiro de 2024. Mas o número impressiona tanto que tende a esconder as perguntas certas: isso resolve tudo? Vale sempre a pena? Quando usar contexto longo de verdade faz sentido?
O que é um token e por que esse número importa?
Antes de falar em milhão, vale esclarecer a unidade. Um token é um pedaço de texto que o modelo processa — algo próximo a uma palavra, mas nem sempre. A palavra "tokens" é um token; "inteligência" pode virar dois ou três. Como referência aproximada: um texto de leitura média em português tem grosso modo um token para cada quatro ou cinco caracteres.
A janela de contexto é o limite de quantos tokens um modelo consegue considerar de uma só vez — tanto o que você envia (entrada) quanto o que ele gera (saída). Pense como a memória de trabalho da sessão: tudo que fica dentro da janela está "visível" para o modelo ao formular uma resposta; o que fica de fora, simplesmente não existe para ele naquela interação.
Modelos de geração anterior operavam com janelas de quatro mil, oito mil, até trinta e dois mil tokens. Suficiente para conversas, documentos curtos, trechos de código. Mas uma base de código corporativa, um processo judicial completo, a transcrição de um dia inteiro de reuniões — esses extrapolavam qualquer limite disponível.
Como chegamos ao 1 milhão: o que o Gemini 1.5 Pro fez diferente
Em fevereiro de 2024, o Google lançou o Gemini 1.5 Pro com uma janela de contexto de 1 milhão de tokens — e depois abriu um preview com 2 milhões. O número é qualitativamente diferente dos predecessores porque muda o que cabe num único pedido.
Grosso modo, 1 milhão de tokens equivale a livros inteiros de extensão média, grandes repositórios de código, muitas horas de transcrição de áudio ou vídeo, ou um acervo extenso de documentos internos — tudo processado numa chamada só. Não uma fatia, não uma seleção amostral: o conjunto inteiro.
Isso importa porque algumas perguntas só têm resposta quando o modelo enxerga o contexto completo. "Existe contradição entre a cláusula 14 do contrato A e o adendo do contrato C?" — para responder isso com segurança, o modelo precisa ler os dois documentos. Com janelas pequenas, você teria que descobrir qual trecho enviar. Com 1 milhão de tokens, você envia tudo.

Casos de uso onde contexto longo resolve de verdade
A janela gigante não é útil para todo tipo de tarefa. Ela brilha em situações específicas:
Análise de documentos volumosos sem pré-seleção. Quando você não sabe onde está a informação relevante dentro de um documento extenso, mandar tudo é mais seguro do que tentar adivinhar o trecho certo. Isso é especialmente valioso em contratos, laudos técnicos, relatórios regulatórios e dossiês jurídicos.
Revisão de bases de código inteiras. Um repositório de médio porte com dezenas de arquivos pode caber numa janela de 1 milhão. O modelo consegue rastrear dependências, detectar inconsistências entre módulos e entender a arquitetura sem que você precise montar manualmente um resumo do código.
Resumo e análise de transcrições longas. Reuniões de diretoria, audiências, entrevistas de pesquisa — a transcrição completa de um dia de trabalho pode ser processada em bloco, permitindo perguntas que cruzam momentos distantes da conversa.
Contexto histórico de conversas e projetos. Em vez de resumir e perder nuances, você mantém o histórico completo acessível ao modelo durante toda a sessão de trabalho.
| Cenário | Janela longa vence | RAG/busca vence |
|---|---|---|
| "Existe contradição no contrato inteiro?" | Sim — modelo precisa ver tudo | Não — você precisaria saber onde buscar |
| "Qual a resposta para esta pergunta frequente?" | Não — base de conhecimento grande, pergunta pontual | Sim — busca o trecho relevante, ignora o resto |
| "Revise toda a arquitetura deste repositório" | Sim — visão global importa | Parcialmente — depende do escopo |
| "Responda perguntas sobre um catálogo de 50 mil produtos" | Não — custo e latência inviabilizariam | Sim — RAG retorna só o produto pedido |
| "Resuma esta reunião de 3 horas" | Sim — transcrição cabe e deve ser lida por inteiro | Parcialmente — depende do que se quer resumir |
Os trade-offs que o número não conta
A janela de 1 milhão de tokens é real. Os custos também são.
Custo proporcional ao uso. APIs de modelos com contexto longo cobram por token processado — tanto de entrada quanto de saída. Enviar 800 mil tokens de documento toda vez que o usuário faz uma pergunta simples pode tornar a operação economicamente inviável dependendo do volume de requisições.
Latência cresce com o contexto. Processar contextos gigantes leva mais tempo. Para aplicações onde a resposta precisa ser quase imediata, janelas muito grandes podem criar uma experiência degradada.
O fenômeno "lost in the middle". Pesquisas mostraram que modelos de linguagem tendem a prestar mais atenção no início e no fim de contextos longos, perdendo informações posicionadas no meio. Isso significa que jogar um documento de 900 mil tokens e esperar que o modelo "veja tudo igualmente bem" é uma expectativa que pode não se confirmar na prática — especialmente quando a informação crítica está enterrada no meio do texto.
Esses três fatores juntos explicam por que RAG (Retrieval-Augmented Generation) — a técnica de buscar dinamicamente só os trechos relevantes antes de gerar uma resposta — continua fazendo sentido mesmo com janelas gigantes disponíveis. RAG não é alternativa ultrapassada ao contexto longo: são estratégias complementares, cada uma com seu domínio de aplicação.
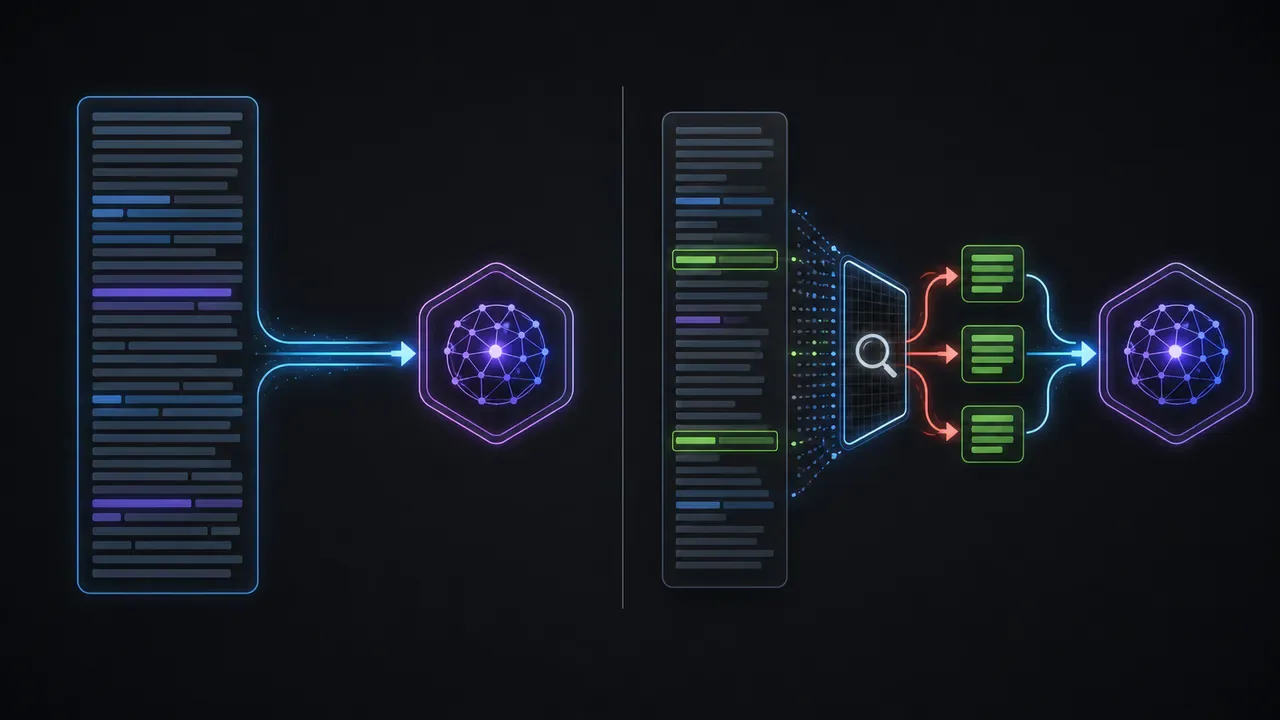
Contexto longo versus RAG: como escolher
A pergunta prática é: para o caso de uso em questão, o modelo precisa ver o documento inteiro, ou precisa encontrar a parte certa do documento?
Se a pergunta pode ser respondida a partir de um trecho identificável — "qual o prazo de entrega para pedidos acima de R$ 500?" — RAG é mais eficiente. Você indexa o documento, recupera o parágrafo relevante, envia só ele. Custo menor, latência menor, e o risco "lost in the middle" some porque o contexto enviado é pequeno.
Se a pergunta exige visão global — "existe alguma inconsistência de prazo neste contrato?" — contexto longo é a resposta certa. Não há trecho para recuperar; você precisa que o modelo leia tudo.
Na prática, sistemas bem projetados para inteligência artificial aplicada a negócios combinam as duas abordagens: usam RAG para consultas pontuais e contexto longo para análises que exigem visão completa. A escolha não é ideológica — é técnica e econômica.
O que isso muda para empresas com documentos volumosos
Para organizações que lidam com grandes volumes de documentação — contratos, processos, manuais técnicos, histórico de atendimento — a janela de 1 milhão de tokens abre possibilidades antes inviáveis:
Análise comparativa de múltiplos documentos longos numa única sessão. Auditoria de consistência em bases de conhecimento extensas. Extração de padrões em acervos históricos sem pré-processamento manual para selecionar o que enviar.
O ponto crítico é que essas possibilidades precisam ser orquestradas com critério. Mandar tudo sem pensar não é estratégia — é desperdício de custo e potencialmente de qualidade. A infraestrutura que suporta aplicações de IA importa tanto quanto o modelo escolhido.
Para empresas que querem treinar IA no próprio conhecimento — manuais internos, histórico de chamados, documentação de produto — a decisão entre indexar para RAG ou usar contexto longo depende do padrão de uso: consultas pontuais frequentes favorecem RAG; análises holísticas ocasionais favorecem contexto longo.
Perguntas Frequentes
Janela de contexto e memória do modelo são a mesma coisa?
Não. Janela de contexto é o limite de tokens numa única chamada — ela zera a cada nova sessão ou quando o histórico extrapola o limite. "Memória" persistente entre conversas requer arquitetura adicional (armazenamento externo, recuperação explícita). A janela grande resolve o problema de "caber tudo numa conversa", mas não o de "lembrar de conversas passadas".
O Gemini 1.5 Pro é o único com janela de 1 milhão de tokens?
Foi o pioneiro. Outros modelos avançaram em suas janelas desde então — o mercado de LLMs evolui rápido. O ponto relevante é que contextos de centenas de milhares de tokens se tornaram acessíveis comercialmente e não são mais exclusividade de laboratórios.
Usar o contexto inteiro sempre garante respostas melhores?
Não necessariamente. O fenômeno "lost in the middle" indica que informações posicionadas no centro de contextos muito longos podem receber menos atenção do modelo. Documentos bem estruturados, com informação crítica no início ou no fim, tendem a produzir melhores resultados do que textos densos onde tudo tem a mesma importância aparente.
RAG vai se tornar obsoleto com janelas cada vez maiores?
Improvável no curto prazo. RAG continua sendo mais econômico para consultas pontuais em bases grandes, e o custo de contexto longo não cai na mesma velocidade que o custo geral dos modelos. As duas abordagens devem coexistir, escolhidas conforme o caso de uso.
Como saber se minha empresa precisa de contexto longo ou RAG?
A pergunta-chave é: a resposta exige visão do documento inteiro, ou pode ser encontrada num trecho identificável? Análises de consistência, revisões globais e perguntas cruzadas sobre múltiplas seções favorecem contexto longo. Consultas pontuais a bases de conhecimento grandes favorecem RAG. Na maioria dos sistemas reais, ambos convivem.
Conclusão
A janela de contexto de 1 milhão de tokens é uma mudança real de capacidade — não marketing. Ela torna viável processar documentos inteiros, repositórios completos e transcrições extensas numa única chamada de modelo, sem a necessidade de fragmentar e pré-selecionar manualmente o que enviar.
Mas como toda mudança técnica significativa, ela vem com trade-offs: custo proporcional ao tamanho do contexto, latência maior e o risco de "lost in the middle" em textos muito longos. RAG continua sendo a escolha mais eficiente para consultas pontuais em bases grandes. As duas abordagens são complementares, não concorrentes.
Para empresas que lidam com documentos volumosos ou querem treinar IA no próprio conhecimento acumulado, a decisão entre essas estratégias tem impacto direto em custo operacional e qualidade das respostas. Na MaxVision Labs, esse é exatamente o tipo de análise que fazemos antes de desenhar qualquer solução de IA — avaliar o padrão de uso, o volume de dados e o objetivo para recomendar a arquitetura certa.
Se você tem dúvidas sobre qual abordagem faz sentido para o seu contexto específico, fale com a equipe.